Consistent Hashing
It's a system design concept which is used in load balancing and partitioning in distributed systems. This is one of the ideas used also by database sharding techniques to distribute data across multiple database instances.
Here consistent means, the hashing is implemented in such a way that, even if new servers/partitions are added, still the existing generated hashes mostly remain same as before. This is where the consistency comes from.
Regular Hashing
In regular hashing, if there are 5 partitions, then each partition is given a value from 0 to 4. Then for a specific key, the hash function then generates an integer value and then mod 5 is applied to the same. This value then determines the partition to which the data will be put into.
Now, when a new server is added, there will be 6 partitions and then mod 6 will be applied. Yet mod 6 will then change hash values of many existing data and this means a lot of data must be moved/migrated to new partition IDs generated by the new hash function.
server = hash(key) % number_of_servers
- The mod N depends always on the size of the partition. Hence adding and removing partitions will always lead to lot of data migration.
- Irrespective of how good the hash function is, applying mod on it at the end will always create same issues.
What consistent hashing does differently?
This solution brings in consistency by ensuring any additions or deletions to partitions won't lead to too many changes in data position. It achieves this by removing the use of mod. Instead it uses the same hash function to generate the positions of the servers on the ring as well as the keys.
Important to keep in mind - Items are placed on a circular track and the item goes to the nearest box available in the clockwise direction.
Normally the size of the key is a 32 or 64 bit integer. Meaning, the allowed positions are . Hence the ring is rarely full.
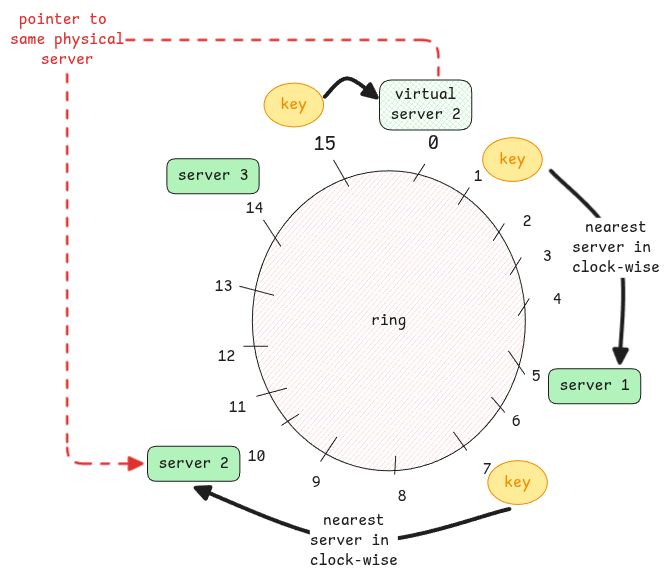
Virtual Nodes
In case there is lot of keys being assigned to the same server, we split create virtual copies of it and use the same hash function to determine its position.
Virtual nodes are just labels. They still point to the same physical shard.
Key Replication
Key replication is another technique where the shard is actually replicated to multiple servers. Which means, when we see that most of the customers are hashed to the same shared, to avoid overloading that shared, we create multiple replicas of it.
Implementation
There exists no circle or ring in the memory to implement this. It's just a regular hash map where hashes are the keys and values are the shards.
This hash map must be sorted so that we can quickly find the nearest shard in the clockwise direction. For this purpose, we can use a TreeMap in Java or a sorted list in Python.