Locking
Locking is a generic concept. You can apply it in many domains. Kernels use it for memory. Databases use it for data sets.
In a database, locking lets you ask the database to lock a data set. This guards it during parallel transactions.
The default lock works like this. Many transactions can read at once. Only one can write at a time though.
In the default lock, writes happen one by one. No check runs on the queued updates. They may write unwanted changes.
This default database lock is called the Readers—writer lock. Reads can happen in parallel. Writes happen one by one.
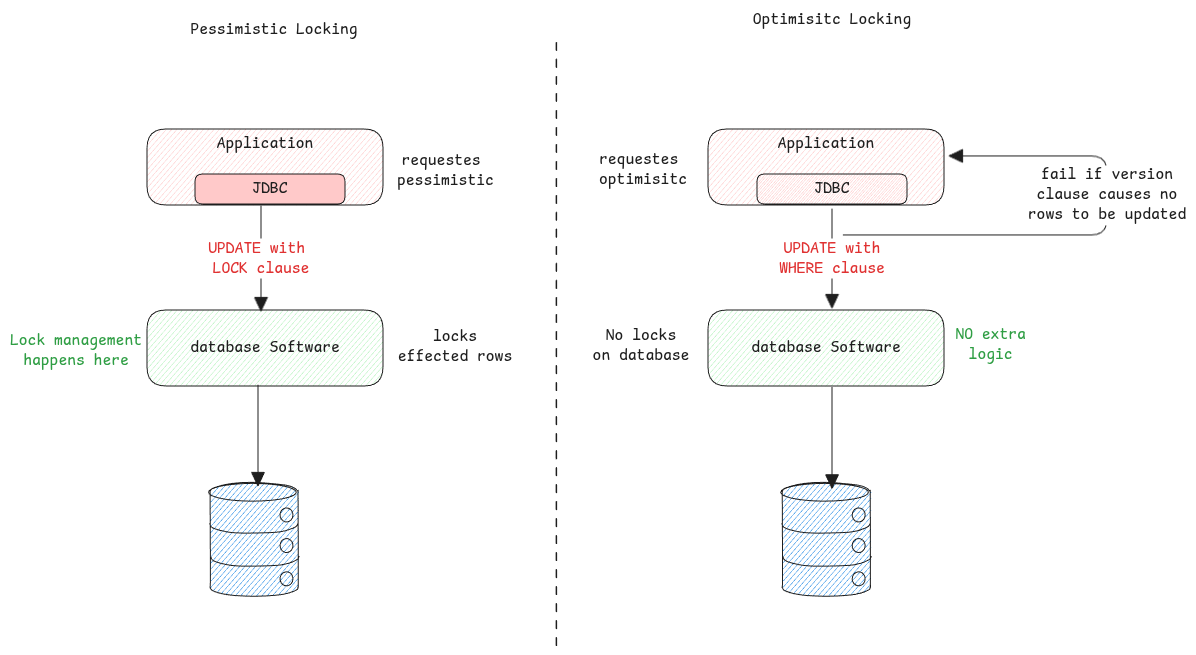
Optimistic Locking
This lock happens at the application level. The app must check if the data changed. If it did, the app must update the query and retry. Or it handles the case some other way.
The name fits because this lock is hopeful. It assumes a race condition is rare.
Version or Timestamp Column
You build it with an extra version or timestamp column.
The app uses this column to check the row. It makes sure no other transaction updated it first.
Pessimistic Locking
This lock is built by the database itself. The app controls how it's applied though. The app specifies it in the query. The database then handles it.
SQL syntax
With special SQL syntax, the app can lock specific data sets.
This syntax isn't common. Each SQL server builds pessimistic locking in its own way.