Vocabulary
Vectors
In general, vectors are multi-dimensional values that represent something. Usually it's an array of numbers. Each number has a specific meaning.
Vectors in AI
In AI, a vector is an array of float numbers that represents a token.
Think of vectors as high dimensional arrays. Every dimension has a meaning. Only the LLM knows what each dimension means.
In natural language processing, each word is an array of co-ordinates in the word space. Similar words sit close to each other. Think of it like location co-ordinates.
In a graph, the nodes connect to each other. The edges define the relation.
In a dimensional space, the co-ordinates define the relation. That's the distance between the points.
Vocabulary Size
English has more than 600k words. But a model learns far fewer tokens. It's somewhere under 50K. This is because the LLM splits words and keeps only the unique parts.
Take the words happiness and unhappiness. In a dictionary, these are two words.
The LLM splits it into 'un' and 'happiness' though. It already knows both. It can read unhappiness without a separate token.
Vocabulary Embedding
In an AI model, each word or token is represented as a vector. This is called vocabulary embedding.
The vocabulary embedding is a matrix of size n x m, where n is the size of the vocabulary and m is the number of dimensions in the vector.
Vocabulary update during training
During training, each token's vector is updated from the context it appears in.
Related tokens get grouped in the vector space.
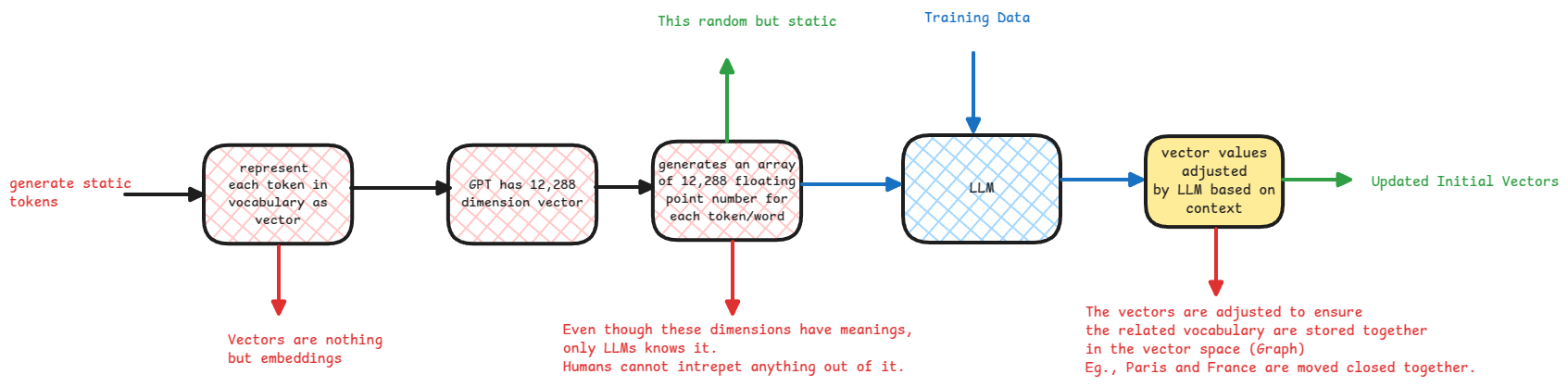
To hold lots of context per word, a word vector has around 12K co-ordinates in ChatGPT.