Tokens
Tokens in Training
Even though English vocabulary contains more than 600k words, the tokens recognized during a model training is very less. It would be somewhere less than 50K. This is because the LLM splits words and takes only unique words as context.
If there are words, happiness and unhappiness. In dictionary, this will be two different words.
But the LLM will split it into 'un' and 'happiness' and since it already knows the meaning of un and happiness, it can easily interpret the meaning of unhappiness without adding it as a separate token.
The vocabulary of an LLM isn't just words. It can be characters, symbols, etc.
Embedding Models
Embedding is about representing existing text, images or videos as numerical values.
The term "embedding" in AI comes from the idea of embedding something complex into a simpler, often lower-dimensional space while preserving its essential characteristics and relationships.
This means, placing the text, images and videos inside another representation space.
Vectors
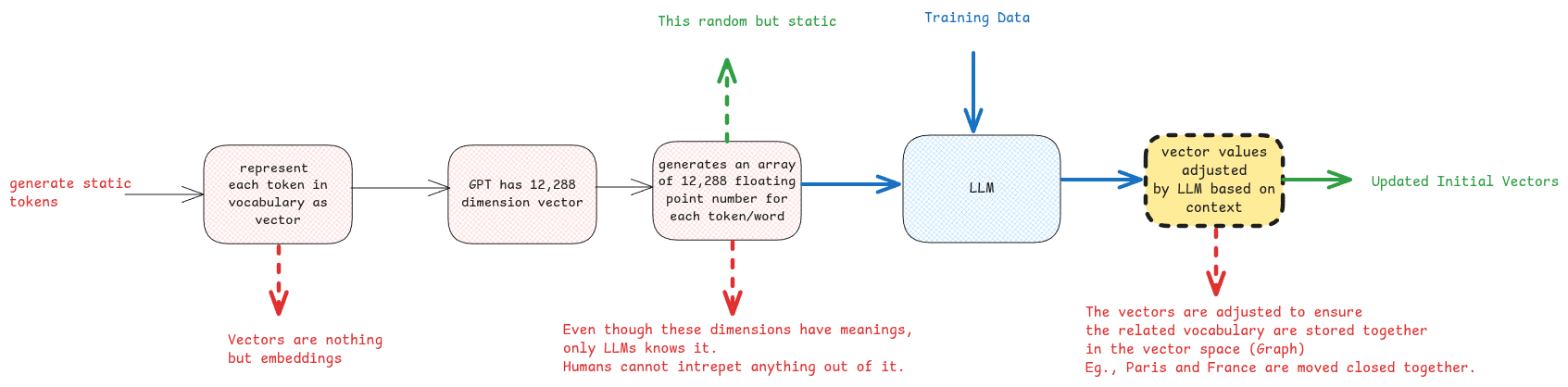
Vectors in general means having a multi-dimensional values to represent anything. This is usually an array of numbers that represents anything.
In AI, vectors are an array of floating point numbers that represents a token.
Think vectors as high dimensional arrays where every dimension has a meaning and only LLM knows the meaning of each dimension.
In case of natural language processing, each word is described using an array of co-ordinates in the word space (graph). This means, similar words will be close to each other this space. You can also think of this like location co-ordinates.
In order to store tons of context for each word, the word vector has around 12K co-ordinates in case of ChatGPT.